
画像生成をしていると思ったような仕上がりにならないことはありませんか?そんな時に活躍するのが、LoRAです。
LoRAを使用すれば、プロンプトが分からなくても雰囲気に近い画像を生成してくれます。
本記事を読むことで、LoRAの特徴、SeaArt AIでのLoRAの作り方がわかります。
2024年1月2日のアップデートによりVIP制限が解除され、SVIP(有料会員)でない方も自由に利用できるようになりました!
LoRAとは
LoRA(ローラ)は”Low-Rank-Adaptation”の略で、少ない計算量で追加学習可能なモデルのことです。
大規模言語モデルによる画像生成を効率的にするためのツールで、さまざまな種類のLoRAが存在しています。
モデルとLoRAの違い
初心者の方はモデルとLoRAの違いに戸惑うことが多いと思います。
モデルは基本的な画風を決定し、生成する画像の大まかなスタイルを定めます。
一方、LoRAはモデルに追加効果を加えるものと考えていただくと理解しやすいでしょう。
LoRAの種類
ここでは、4種類の代表的なLoRAを紹介します。
画風LoRA
線画

水彩画
ジグソーパズル画
服装LoRA
浴衣

メイド服

学生服

背景LoRA
コンビニ背景

学校の教室の背景
旅館の背景
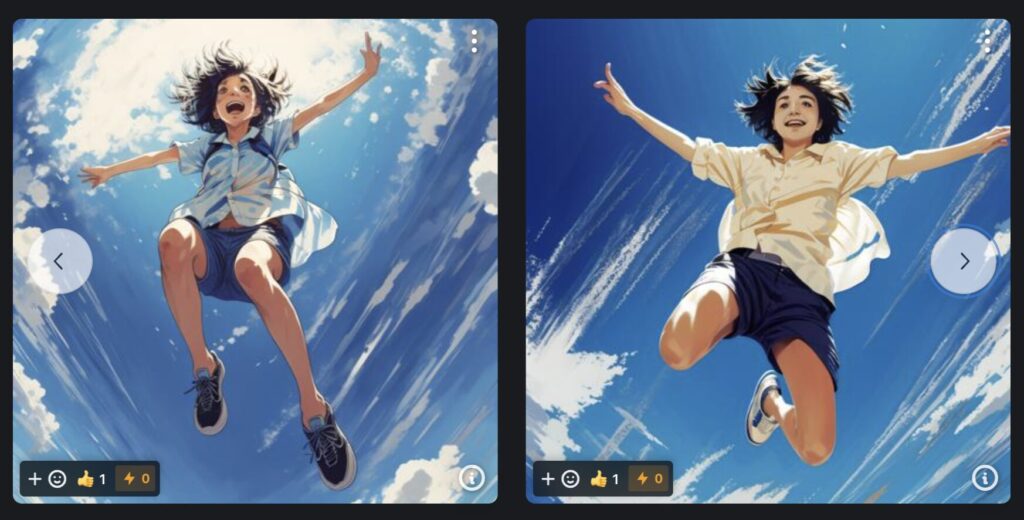
ポーズLoRA
あぐらをかくポーズ

片足で立つポーズ

ジャンプしているポーズ
SeaArt AIでLoRAを作成する方法
先ほどはLoRAの種類を紹介しましたが、実際にLoRAを作ってみたいと思った方はSeaArt AIで簡単に作成できます。
SeaArt AIでのLoRAの作成方法は次のとおりです。
- データセット作成
- パラメータ設定
- 画像のアップロード(最大200枚)
- LoRAトレーニング開始
- LoRAの公開
- 奨励プログラムの参加(任意)
トレーニングへのアクセスとデータセット作成
上部にあるトレーニングへアクセスします。
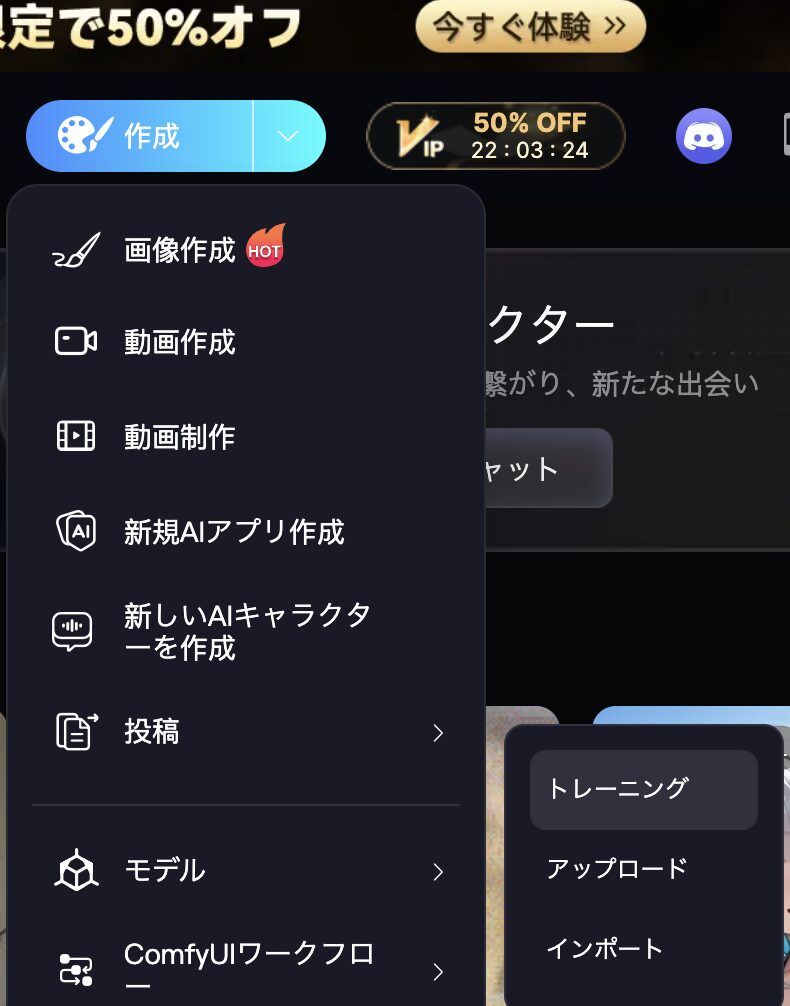
次に、「データセット作成」をクリックします
パラメータ設定
プリセットが用意されているので、以下のなかから自由に選択しましょう。

基本的なパラメータが反映されます。
Pony Diffusion、FLUX.1、Stable Diffusion 3.5 Medium (SD3.5M)、Stable Diffusion 3.5 Large (SD3.5L) について、それぞれの特徴を紹介します。
1. Pony Diffusion
コミュニティ主導(特にCivitaiで人気)。元々はアニメ「My Little Pony」に特化したモデルとしてスタートしましたが、現在はアニメやイラスト全般に対応しています。ベースモデルは、Stable Diffusion XL (SDXL)を基盤とした派生モデルです。独自のスコアタグシステム(score_9, score_8_up)などを使用し、品質を制御します。
2. FLUX.1
Black Forest Labsが設立したサービスです(Stable Diffusionのオリジナル開発者)。Stable Diffusionの後継として設計された次世代モデルで、最大2メガピクセルの高解像度の画像生成が可能です。アニメから実写まで幅広いスタイルに対応します。
3. Stable Diffusion 3.5 Medium (SD3.5M)
Stability AIが開発した新しいモデルで、パラメータ数は26億。リリース日は、2024年10月29日です。SD3シリーズの軽量モデルで、プロンプト追従性はFLUX.1に勝るが、美的品質ではやや劣ります。プロンプトの曖昧さによる出力のバラつきが大きいのが難点です(意図的な設計)。
4. Stable Diffusion 3.5 Large (SD3.5L)
SD3シリーズの上位モデルで、パラメータ数は80億。アニメ、実写、アートなど多様なスタイルに対応します。プロンプトへの忠実度が高く、複雑なシーンや詳細な描写を正確に生成できます。
私なら、今流行りの Pony Diffusion か FLUX.1 で作成したいですね♪
高級設定

高級設定では、個別にパラメータ設定ができるようになっています。いくつか紹介します。
とりあえず、わからなければ無理に触る必要はないです。
ネットワークモジュール
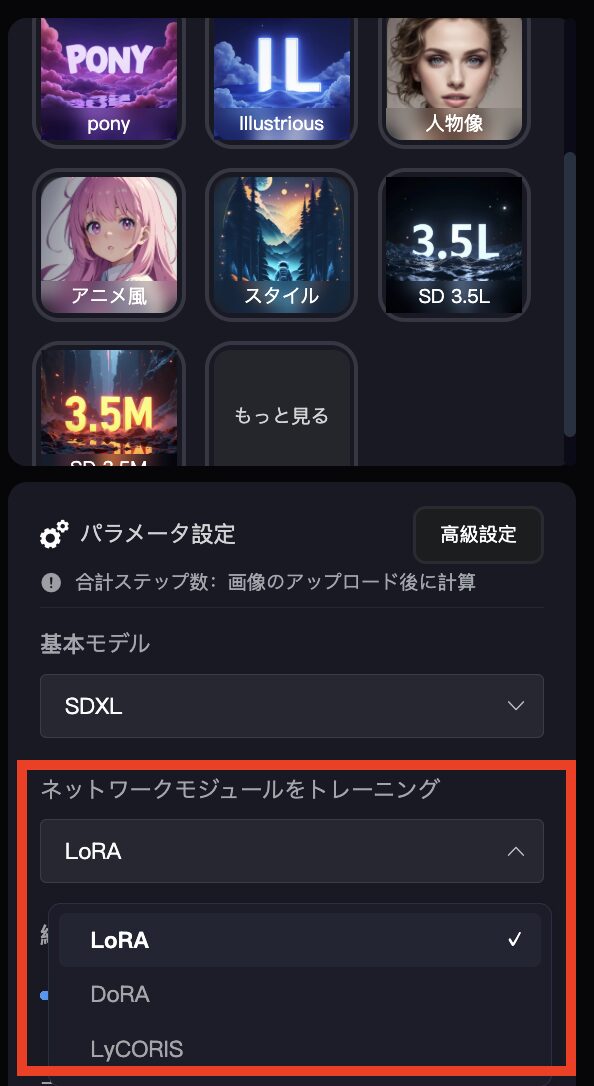
続いては、ネットワークモジュールについてです。
そもそもネットワークモジュールは、画像生成AIに「新しいスキルを少しだけ教える」ための小さな道具です。大きなAIモデル全体をいじるのは大変なので、特定の絵柄やキャラを覚えさせるために、軽い「追加パーツ」を使います。これがLoRA、DoRA、LyCORISです。
1. LoRA (Low-Rank Adaptation)
LoRAは、一番簡単で軽いモデルです。AIに「このキャラや絵柄をちょっと覚えて!」と教えるのに使います。ファイルが小さいので、学習も生成もサクサクですが、超複雑な絵柄や細かいディテールは苦手です。
2. DoRA (Weight-Decomposed Low-Rank Adaptation)
DoRAは、LoRAの進化版です。LoRAより丁寧に書かれていて、もっと本格的な絵柄やスタイルをAIに教えられます。ただし、学習するのに時間がかかります。LoRAより絵のクオリティが高いので、芸術や実写風の絵柄に向いています。
3. LyCORIS
LyCORISは、LoRAをベースに作られたやつです。超細かいキャラの服、アニメの背景、独特な絵柄の再現が得意です。細かい部分までこだわったモデルを作りたいときに便利です。
| モジュール | 使いやすさ | 絵のキレイさ | どんな絵にいい? |
|---|---|---|---|
| LoRA | ★★★★★ | ★★★ | キャラ、簡単な絵柄 |
| DoRA | ★★★★ | ★★★★ | 芸術、細かいスタイル |
| LyCORIS | ★★★ | ★★★★★ | 超細かい絵、背景 |
結論、初心者ならLoRAから始めるのがおすすめです!アニメキャラや簡単な絵柄をサクッと作りたいときに便利です。
画像のアップロード
プリセットとモジュールを選択したら、好きな画像を最大200枚アップロードします。※キャラクターの場合、異なる顔をアップロードするとLoRAトレーニングできないので、顔は統一してください。
ここでは、漫画『SPY×FAMILY』のヨルさんの画像を9枚アップロードしてあります。データセット名は、「Yolforger」にしました。
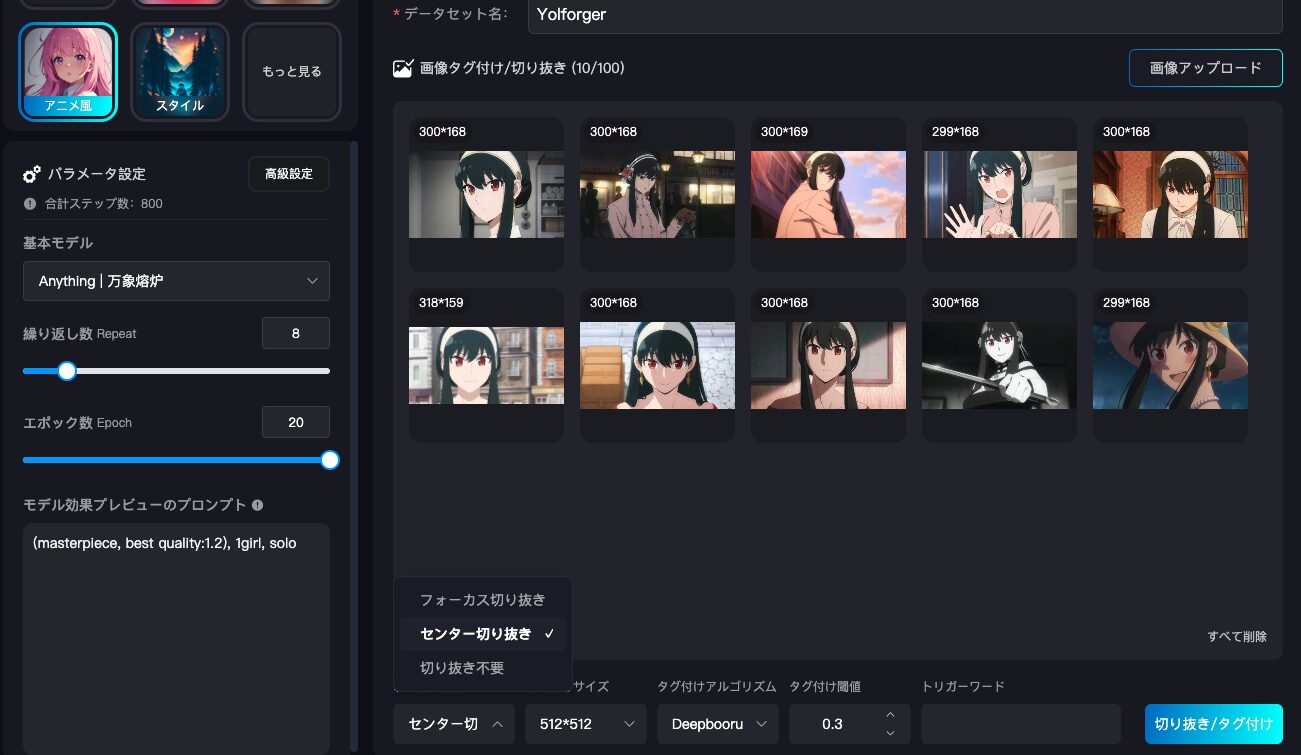
下部にある、切り抜き方式は「センター切り抜き」にします。これを選ぶことで、画像の主要な被写体を自動的に切り抜いてくれます。
前はこんな機能なかったのに、進化してる・・・
タグ付けアルゴリズムは、Deepbooruが単語による画像の説明、BLIPが文による画像の説明です。
トリガーワードは、生成される画像の内容や特徴を制御するために入力されるキーワードやフレーズのことを指します。今回もし入力するとしたら、「Yolforger」です。
つまり、トリガーワードは生成したい画像のコンセプトや条件を言語的に指定するための手がかりとなります。モデルはこれらのトリガーワードから画像の内容や特徴を”推測”して生成を行います。

問題なければ、「切り抜き/タグ付け」を押します。
切り抜き/タグ付け後
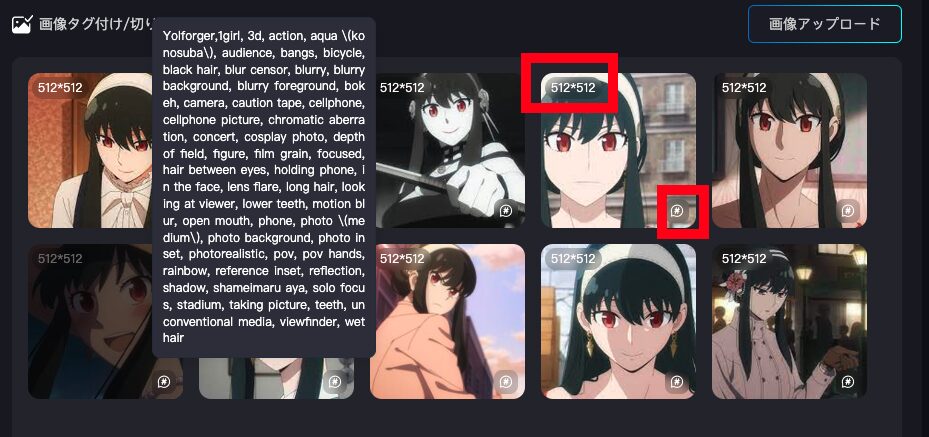
切り抜き/タグ付けが完了すると、画像のサイズが変更され、右下にマークが付きます。このマークにカーソルを合わせると、タグまたは文による説明が表示されます。先ほど、Deepbooruを選択したので、単語で説明が表示されています。
画像をクリックするとタグの登録・削除が行えます。
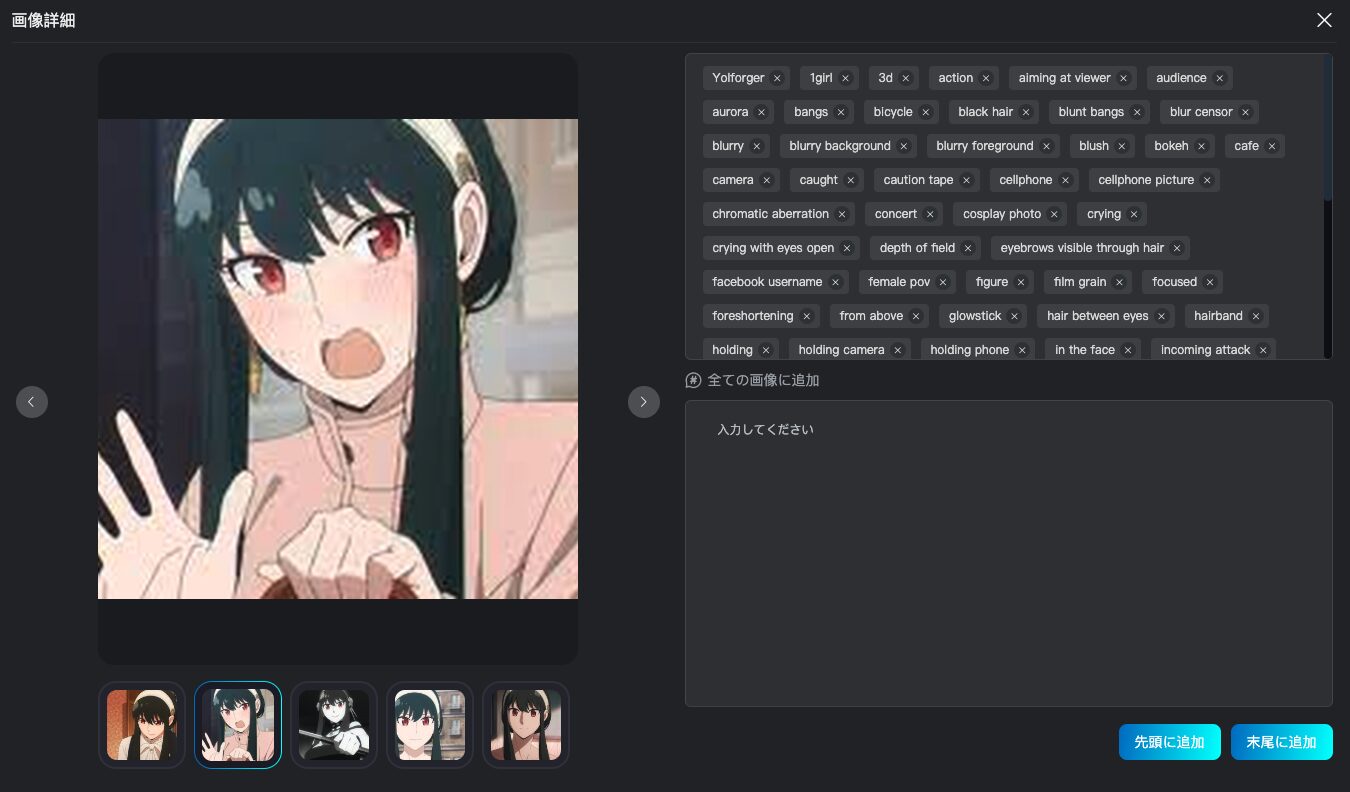
すべてが完了したら、トレーニングに移ります。
LoRAトレーニングの開始
右上にある「今すぐトレーニング」のボタンを押せば、開始されます。今回の予想コスト消費は128です。
それでは、レッツゴー♪
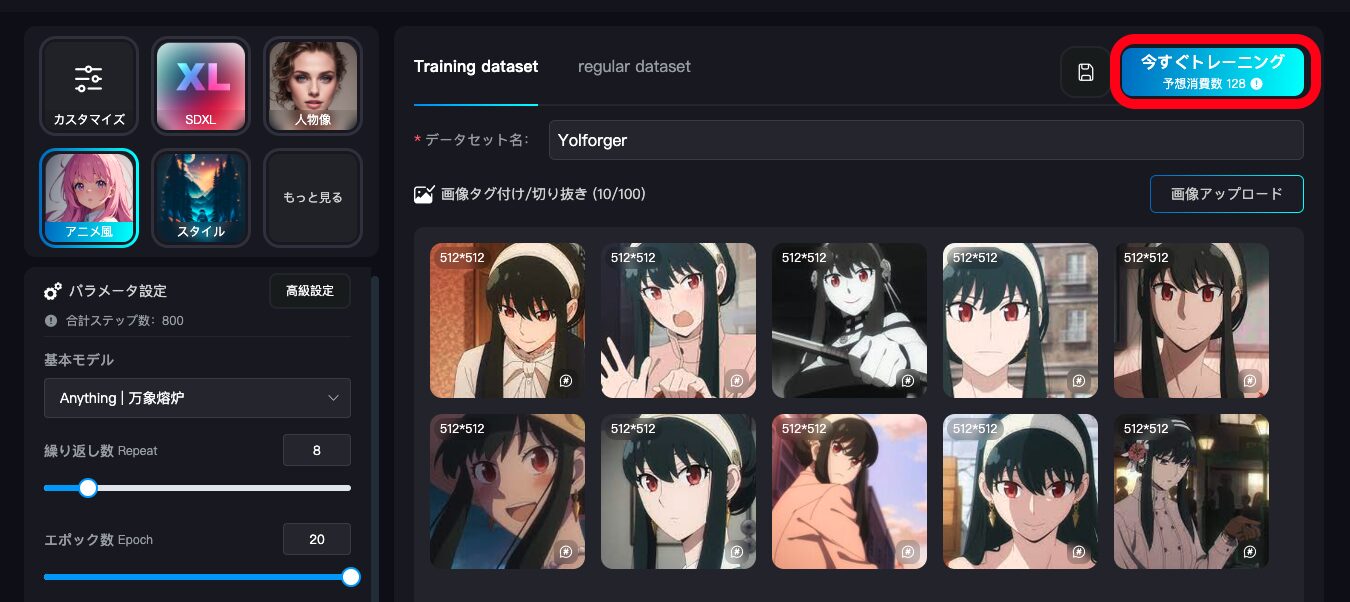
ちなみに、LoRAトレーニングのコインが無い人は課金するか、以下のタスクを完了させることでコインをゲットできますよ。
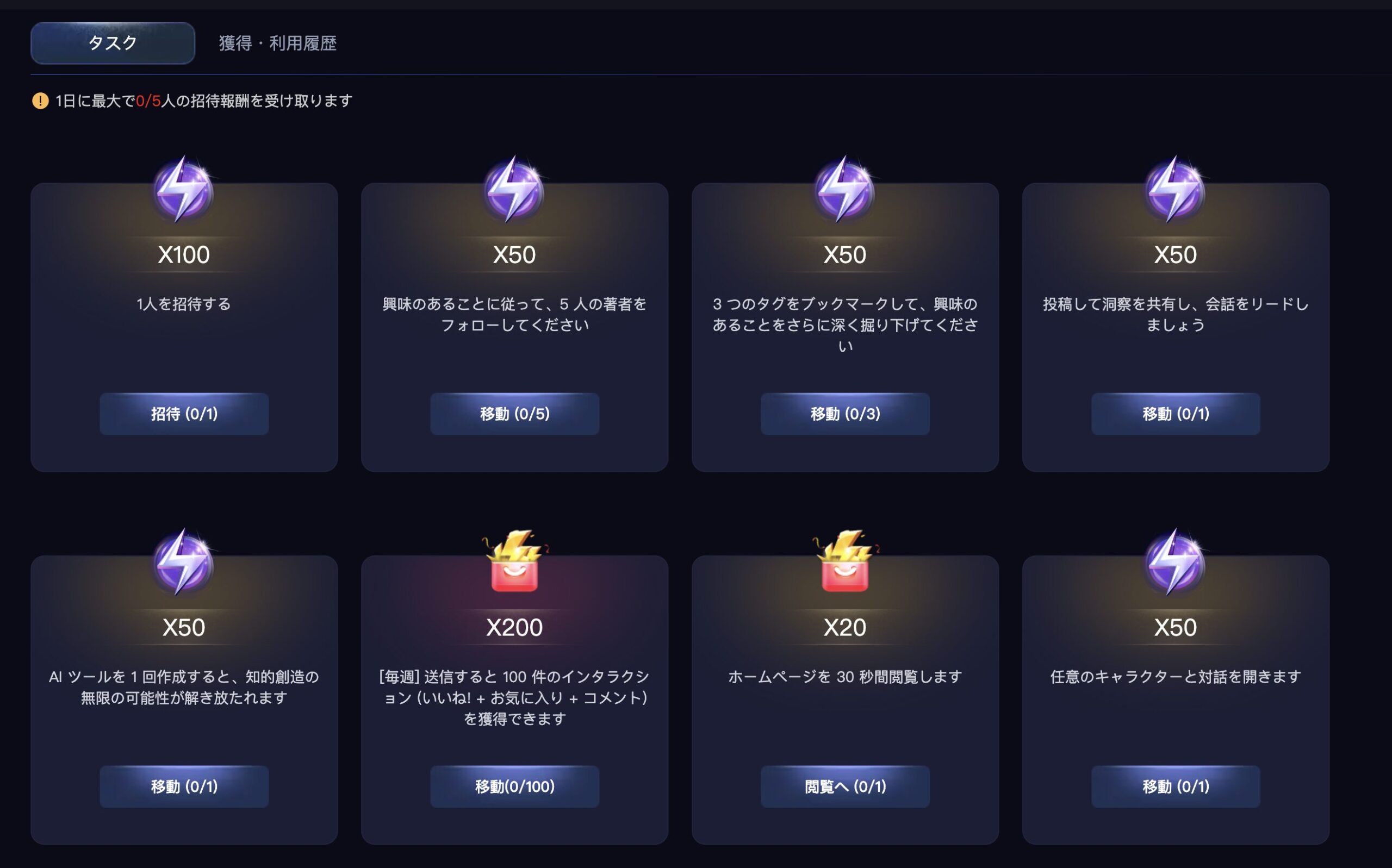
LoRAトレーニング中は、さまざまなサンプル画像が表示されます。
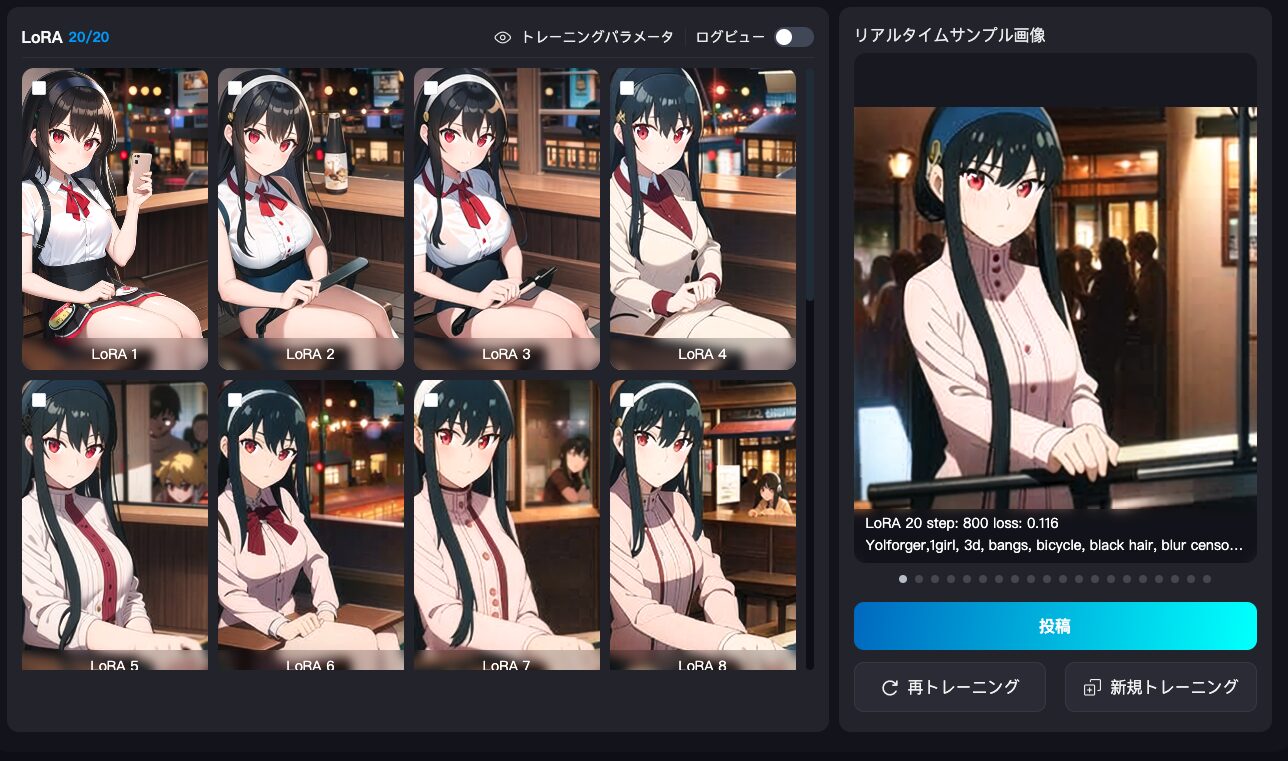
ログビューを開いて損失値をチェックすることもできます。通常、曲線が滑らかで徐々に低下していれば問題ありません。
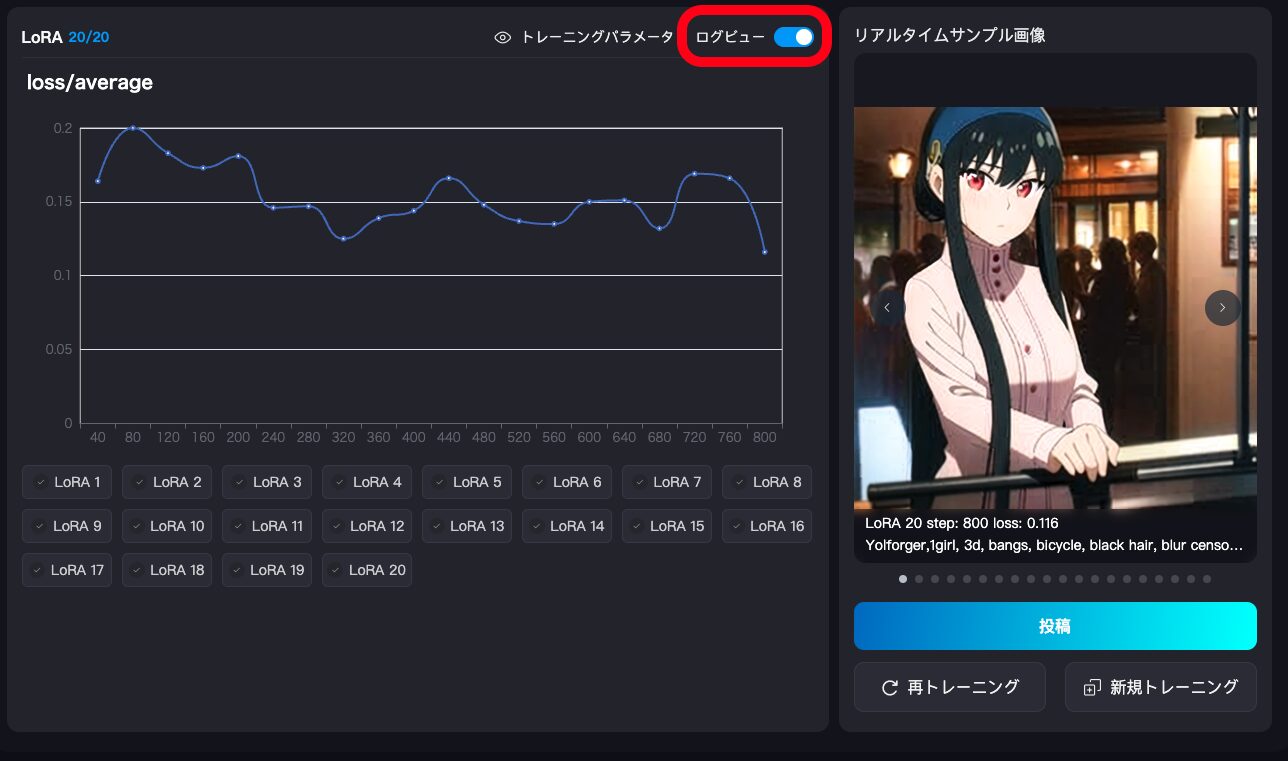
余談ですが、実際にかかったコストは207と、予想よりかかりオーバーしてしまいました・・・
あとは、「投稿」を押せばLoRAを公開できます。
LoRAの公開
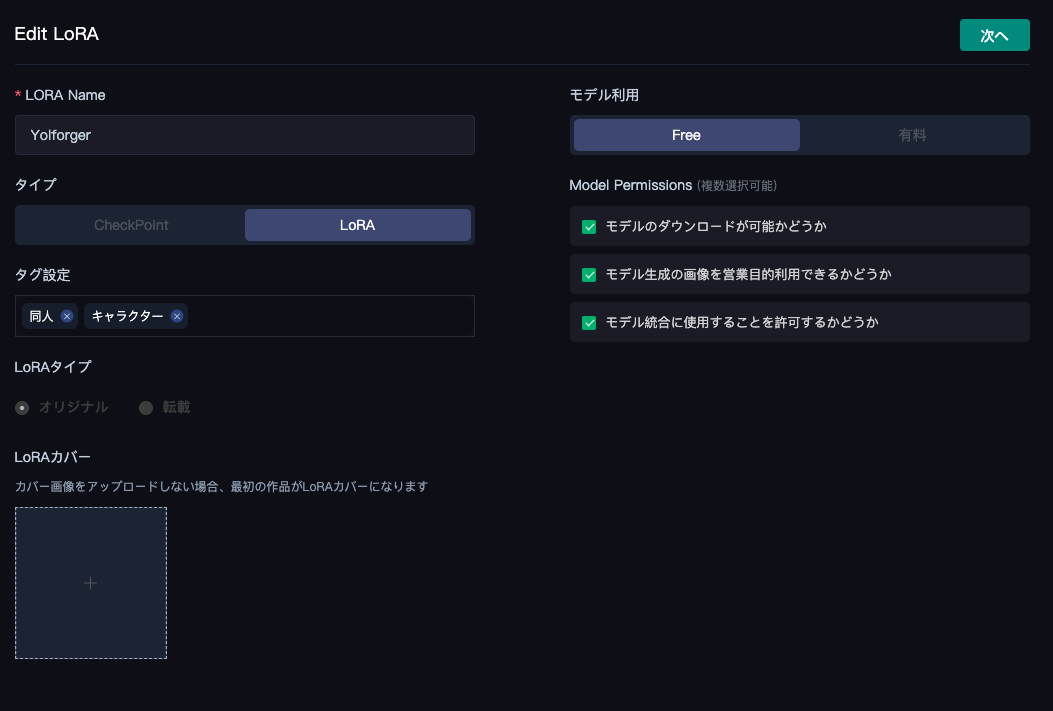
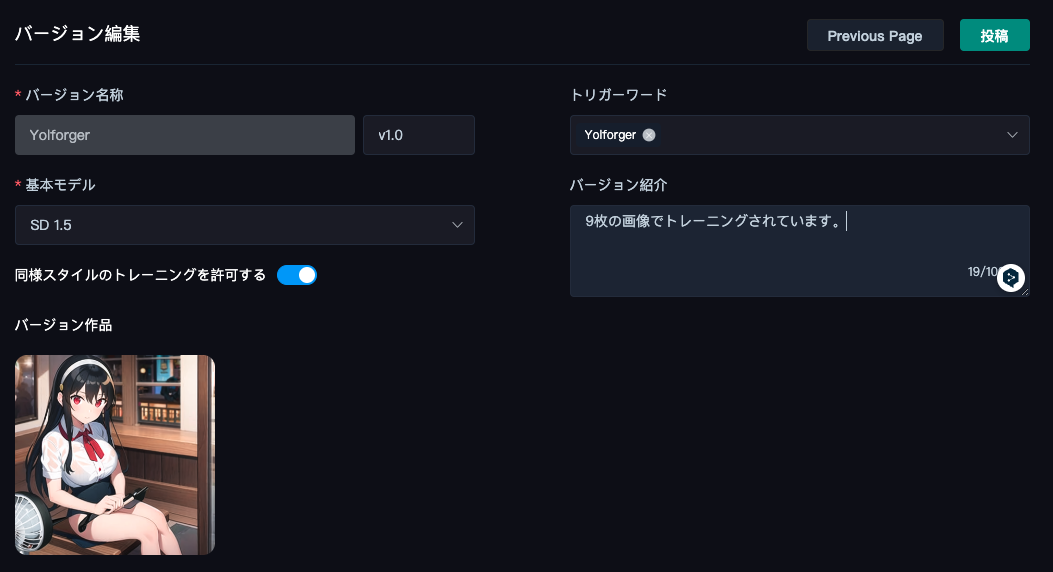
投稿を押すと以下のような画面になります。
名前、タグ、モデル利用、モデル権限を設定し、「次へ」
バージョンにv1.0と記入し、基本モデルSD1.5、トレーニングで設定したトリガーワード、バージョンの紹介を記入します。
「投稿」を押せば、完了です。
\noteにて禁断のAI美女画像の作り方を公開中/

奨励プログラムの参加
最後に、「奨励プログラム」の説明です。
2024年3月4日から新たに「奨励プログラム」が開始されました。これに参加すれば、自分で作成したLoRAが使われる度にポイントが貯まり、その数に応じて収益を得ることができます。
ぜひ、参加してみましょう。
プロフィールの矢印をクリックします。
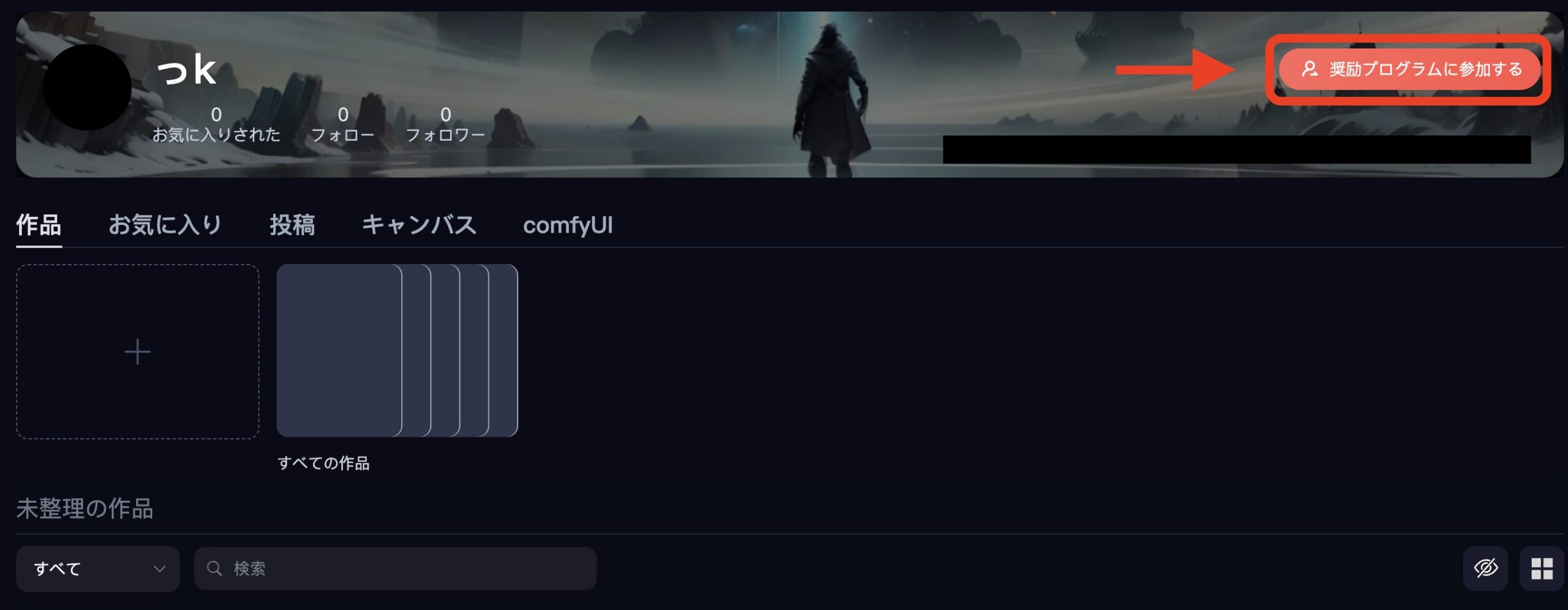
作品ページに移動するので、上にある「奨励プログラムに参加する」をクリックするだけです。
モデルなどが使用されるたびに、ポイントが貯まっていき、貯まった分は月末に送付されます。
私は3月16日から3月31日までに708ポイント獲得しましたが、0.21ドルの収益が発生していました。日本円にすると31円ほどです。これを少ないととるか、多いととるかはあなた次第です!
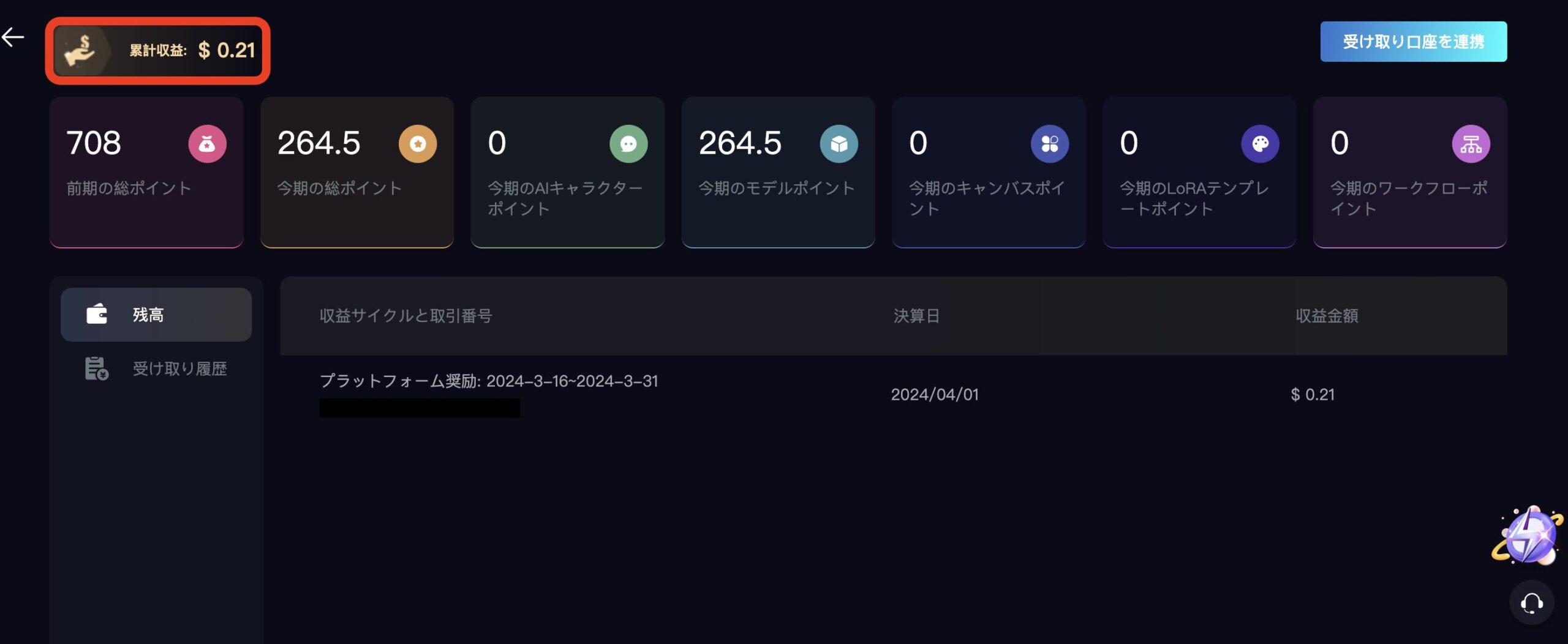
収益を受け取るには、口座の登録も忘れずに行いましょう。
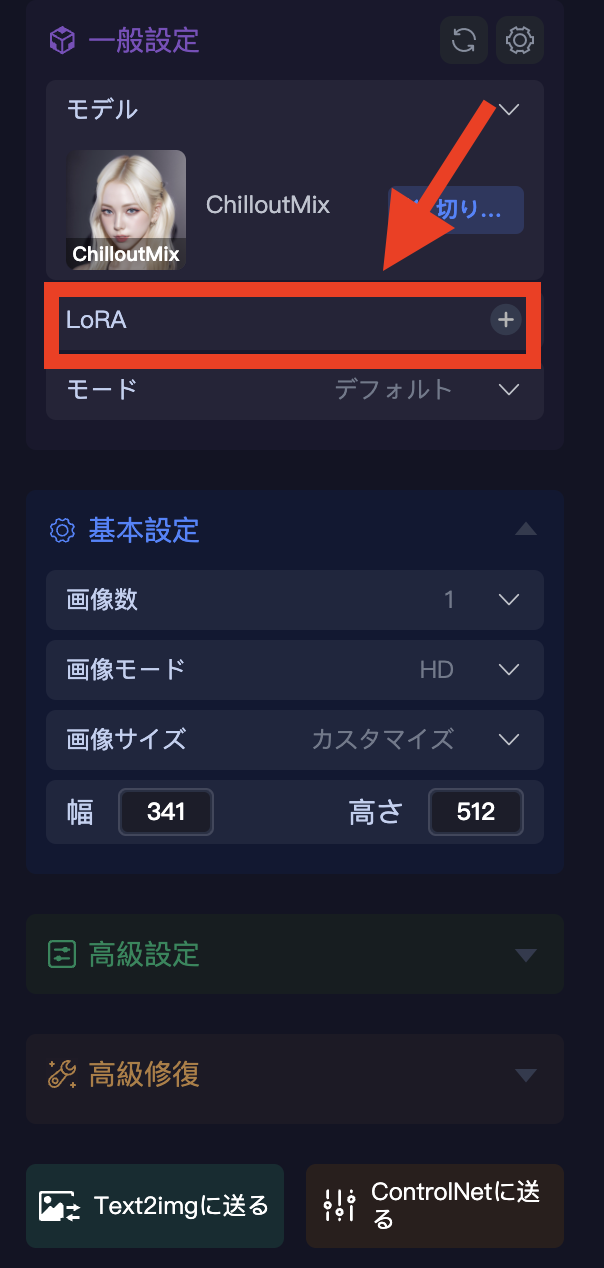
作成したLoRAの使い方
作成したLoRAの使い方です。
トレーニングで作成したLoRAを使うには、[創作ページ]にアクセスし、画面右側のLoRAを選択します。
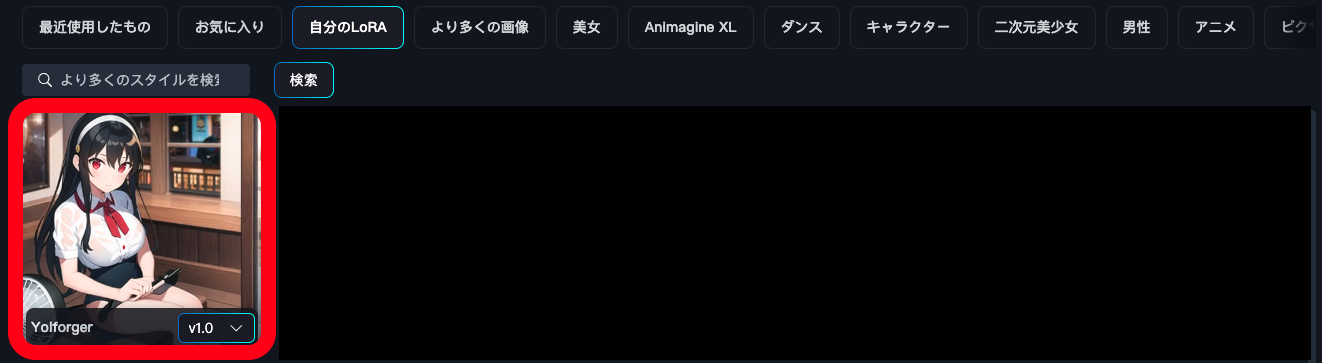
「自分のLoRA」から、先ほど作成したLoRAが選べるようになっているはずです。
実際に、LoRAを使って生成した画像です。生成する際は、トリガーワードの入力を忘れないようにしてくださいね。


髪型や目、輪郭などヨルさんっぽさが反映されているのが分かるかと思います。
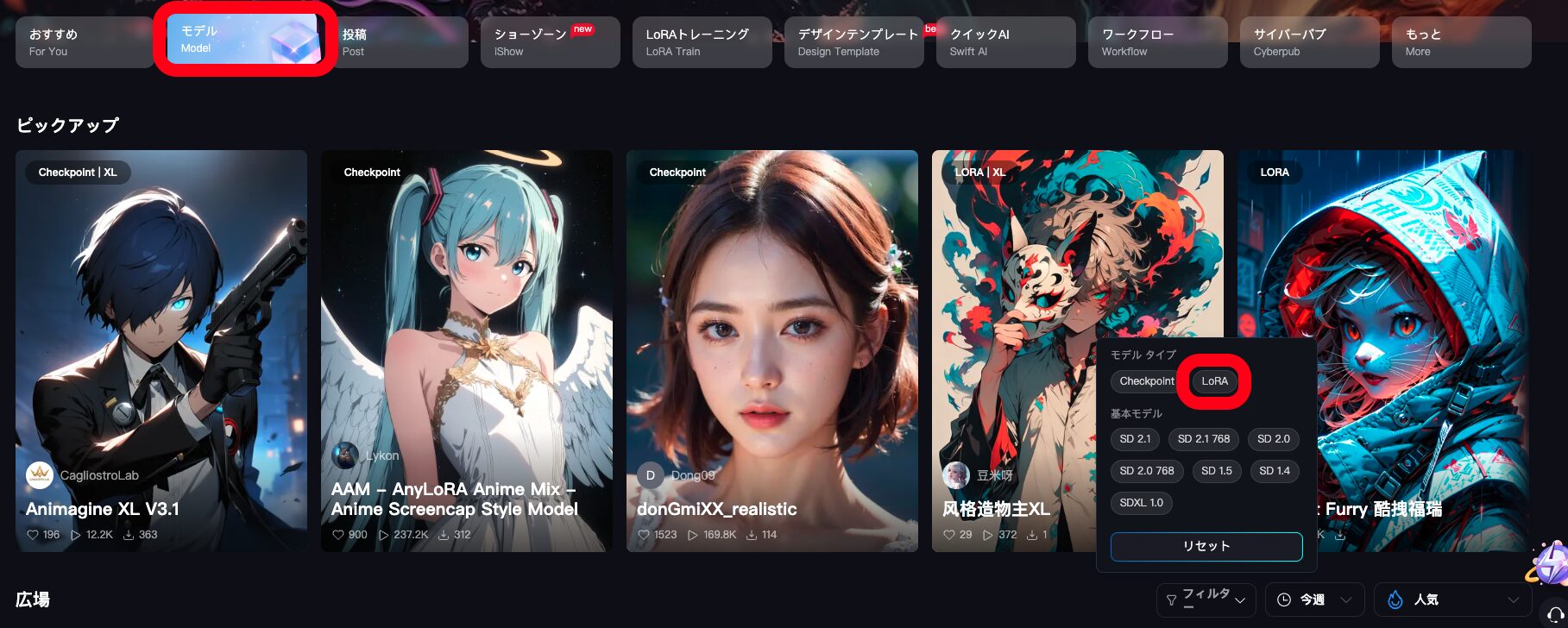
他人が作成したLoRAを探す方法
SeaArt AIでLoRAを探すにはホームの「モデル」から、フィルタの「LoRA」をクリックすればOKです。
まとめ
本記事では、SeaArt AIによるLoRAの作成方法について解説しました。
SeaArt AIでのLoRA作成は無料でトレーニングを開始できます。ただし、スタミナかコインが必要なので、足りない場合はタスクで稼ぐか課金が必須です。
LoRAを利用して、満足いく画像を生成してみましょう。
SeaArtについて、もっと知りたい方はSeaArt(シーアート)の使い方!特徴や機能、安全性は?【画像生成AI】の記事で詳しく解説しています。


コメント