
2025年5月7日に発表された強化学習フレームワークZeroSearchは、大規模言語モデル(LLM)が外部検索エンジンなしで検索能力を高めるための新しい仕組みです。
本記事では、ZeroSearchの仕組みやメリット、従来の手法との違いを解説します。
ZeroSearchとは?検索エンジン不要のLLM強化法
ZeroSearchは、Alibaba傘下のTongyi Labが開発した技術で、LLMの検索能力を向上させるために生まれました。
ZeroSearchはなぜ必要か
従来、LLMは外部検索エンジンから情報を取得して回答精度を高めていましたが、以下の課題がありました。
ZeroSearchは、LLM自体が検索結果を生成することで、これらの課題を克服。外部APIを一切使わず、内部で情報を処理します。
ZeroSearchの基本構造
ZeroSearchは、2つのステップでLLMを検索モジュールに変えます。
このプロセスにより、LLMは実際の検索エンジンを使わずに検索をシミュレートし、高精度な回答を導き出します。
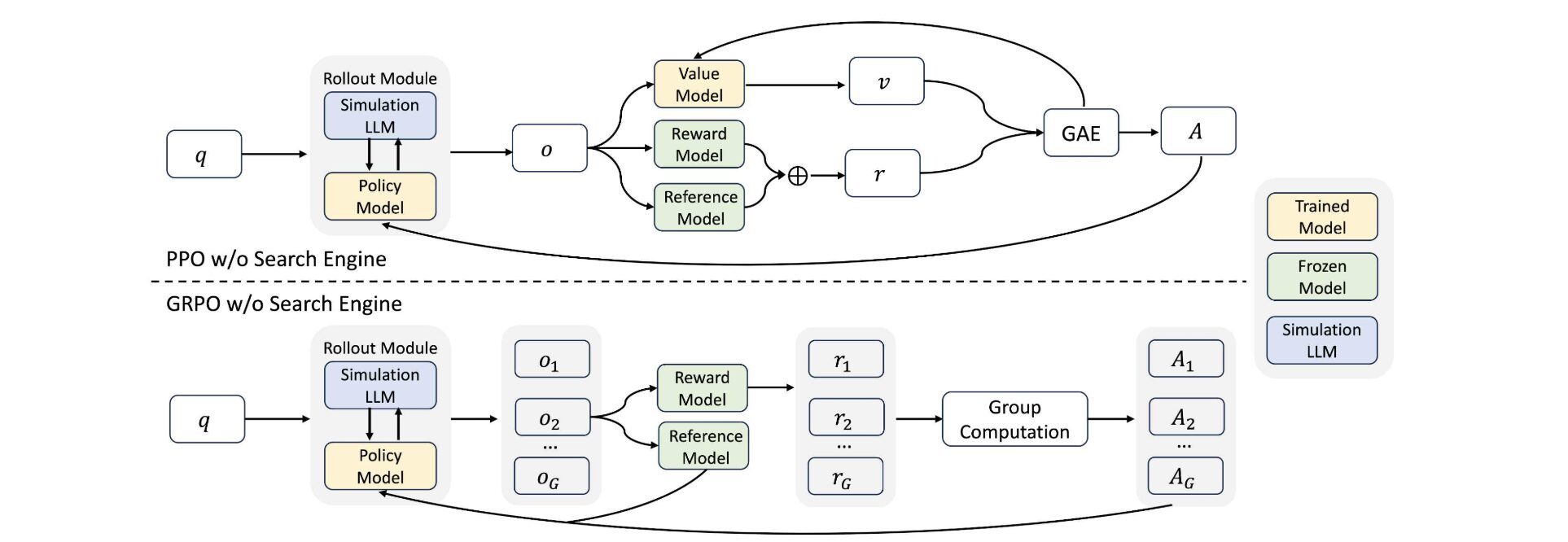
ZeroSearchの仕組み:LLMが検索エンジンになるプロセス
ZeroSearchの核心は、LLMを検索エンジンのように機能させる技術にあります。教師あり学習と強化学習を組み合わせ、LLMが自ら情報を生成・分析する能力を養います。
教師あり微調整(SFT)による検索モジュールの構築
ZeroSearchの第一ステップは、LLMを「検索モジュール」に変換することです。
このステップにより、LLMは外部検索エンジンなしで文書を生成する基盤を獲得します。
カリキュラムベースの強化学習による推論力の強化
第二ステップでは、強化学習を用いてLLMの検索能力を段階的に向上させます。
p_i = p_s + (p_e – p_s) \cdot (i/m)^{b-1}
(p_s=初期ノイズ、p_e=最終ノイズ、(i)=ステップ、(m)=総ステップ、(b)=4)
この戦略により、LLMは困難なシナリオでも正確な情報を抽出する能力を身につけます。
性能データによる実験結果の裏付け
ZeroSearchの性能は、NQ、TriviaQA、HotpotQAなどのデータセットで検証済みであり、以下は主な結果です。
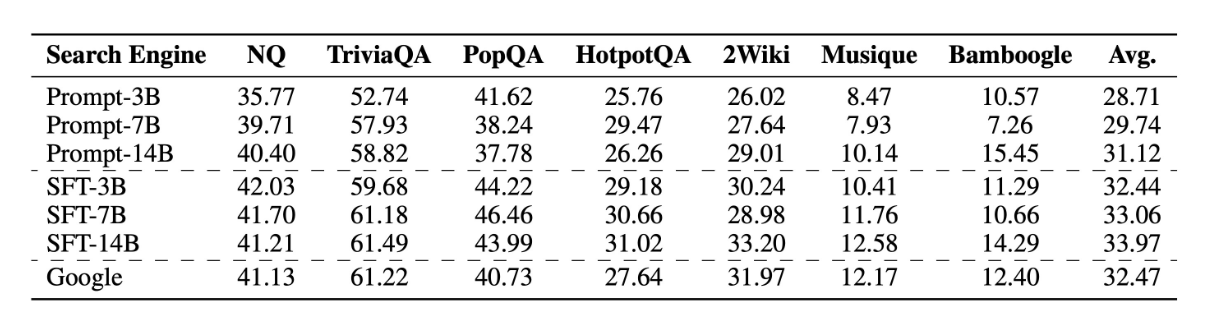
たとえば、NQデータセットではZeroSearch-instがEMスコア43.24を記録し、従来手法(41.46)を上回りました。
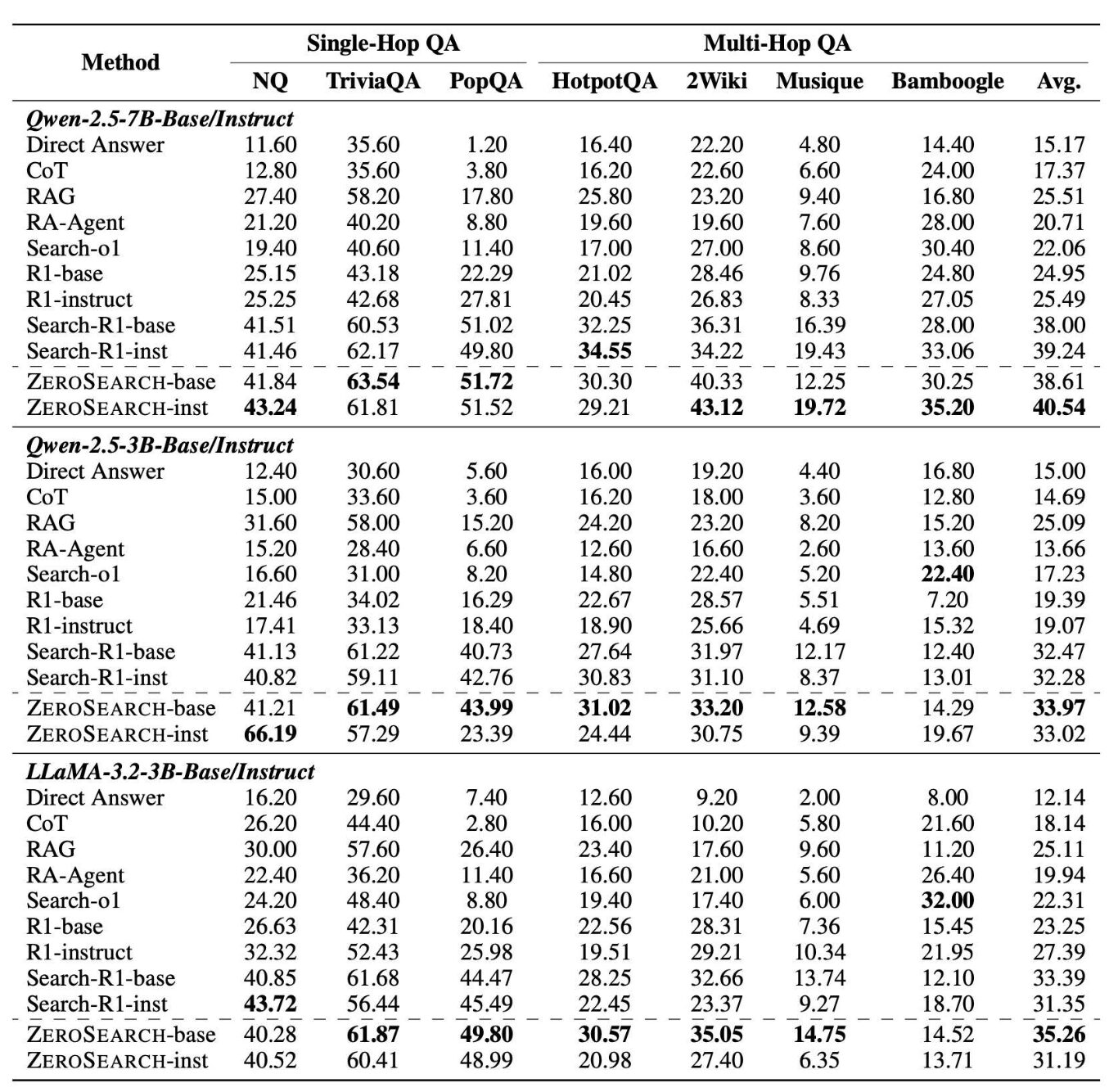
ZeroSearchのメリット:コストと性能の両立
ZeroSearchは、コスト削減と高性能を両立する点で優れており、安定した学習環境が手に入ります。
APIコストゼロの経済性
ZeroSearchの最大のメリットは、APIコストをゼロに抑える点です。
以下の表は、約64,000クエリでのコスト比較です。
| 手法 | クエリ数 | トレーニング時間 | 使用GPU | APIコスト | GPUコスト | 総コスト |
|---|---|---|---|---|---|---|
| SFT-3B | ~64,000 | ~12時間 | 1 × A100 GPUs | $0.0 | $17.7 | $17.7 |
| SFT-7B | ~64,000 | ~12時間 | 2 × A100 GPUs | $0.0 | $35.4 | $35.4 |
| SFT-14B | ~64,000 | ~12時間 | 4 × A100 GPUs | $0.0 | $70.8 | $70.8 |
| ~64,000 | ~12時間 | なし | $586.7 | $0.0 | $586.7 |
この表からもわかるようにZeroSearchは、14Bモデルでも総コスト$70.8で、Googleの$586.7に比べ88%削減しています。
7Bモデルなら$35.4で16分の1のコストで済みます。
Google検索に匹敵・超える精度
ZeroSearchは、検索性能において驚異的な成果を上げています。
7Bパラメータのモデルでは、Google検索と同等の回答精度を実現し、EMスコアで比較しても遜色ありません。さらに、14Bモデルでは、特定のデータセットにおいてGoogle検索を上回る性能を発揮していることがわかります。
生成文書の品質を制御することで、安定した学習プロセスを確保し、信頼性の高い結果が生まれます。限られたリソースでも高品質な検索能力を手に入れることができます。
幅広いモデルとアルゴリズムに対応
ZeroSearchは、さまざまなモデルやアルゴリズムに柔軟に対応する高い汎用性が特徴です。
Qwen-2.5(3B、7B、14B)やLLaMA-3.2といったベースモデルから、指示調整済みモデルまで幅広く適用可能。PPO、GRPO、Reinforce++など多様な強化学習アルゴリズムとも互換性があります。
研究者や開発者は自身の環境やニーズに合わせてZeroSearchを簡単に導入でき、異なる設定での実験や実装がスムーズに行えます。
ZeroSearchとRAGの比較:どちらが優れている
ZeroSearchは、従来の検索拡張生成(RAG)とどう違うのでしょうか?
RAGは外部データベースや検索エンジンを使う手法ですが、ZeroSearchはLLM内部の知識を活用します。
RAGは外部情報を活用
検索拡張生成(RAG)は、外部のデータベースや検索エンジンから情報を取得し、LLMの回答精度を高める手法です。
クエリに基づいて信頼できる外部ソース(ウェブ記事や自社データなど)から関連情報を検索し、取得したデータをLLMに提供して回答を生成します。
最新情報や特定分野の知識を簡単に組み込め、リアルタイム性や専門性が求められるタスクに適しています。
ただし、インデックス構築やAPIコールに伴うコストが発生する点が課題です。
ZeroSearchは内部知識を活用
ZeroSearchの最大の強みは、LLMが持つ内部知識を活用して検索をシミュレートする点にあります。
外部の検索エンジンやデータベースを使わず、LLM自体がクエリに応じた文書を生成し、それを検索結果として利用します。
そのためAPIコストが一切かからず、経済的な運用が可能です。また、生成文書の品質を人為的に制御できるため学習プロセスが安定し、信頼性の高い結果を得られます。
ただし、リアルタイムの最新情報には対応しにくい点に注意が必要です。
使い分けのポイント
ZeroSearchとRAGは、それぞれ異なる強みを持つため、用途に応じた使い分けが重要です。
【RAGとZeroSearchの比較】
| RAG | ZeroSearch | |
|---|---|---|
| 情報源 | 外部データベース/検索 | LLM内部の生成文書 |
| APIコスト | 高い | ゼロ |
| リアルタイム性 | 高い | 低い |
| 学習の安定性 | 不安定(品質依存) | 安定(品質制御可能) |
| 適用例 | 最新情報が必要なタスク | コスト重視の汎用タスク |
このように、RAGは最新ニュースやリアルタイムデータが必要な場合に最適で、ZeroSearchはAPIコストを抑えたい場合や汎用的な知識で十分な場合に適してます。
タスクの要件や予算に応じて、両者を効果的に選択することで、最適なAIシステムを構築できます。
ZeroSearchの活用例
ZeroSearchは、幅広いシーンで活用できる技術です。
小規模なECサイトがZeroSearchを活用して顧客からの問い合わせ対応AIを構築すれば、APIコストを大幅に削減しながら、Google検索並みの精度で回答を提供できます。
GitHubやHugging Faceで公開されているモデルを活用すれば、すぐに実験を開始することも可能です。
まとめ
ZeroSearchは、外部検索エンジンに頼らずLLMの検索能力を強化する画期的なフレームワークです。
APIコストをゼロにし、Google検索と同等以上の性能を実現するこの技術は、スタートアップから研究者まで幅広いユーザーに活用できる技術です。RAGとの使い分けを理解し、適切なシーンで活用すれば、効率的かつ高性能なAIシステムを構築できます。


コメント